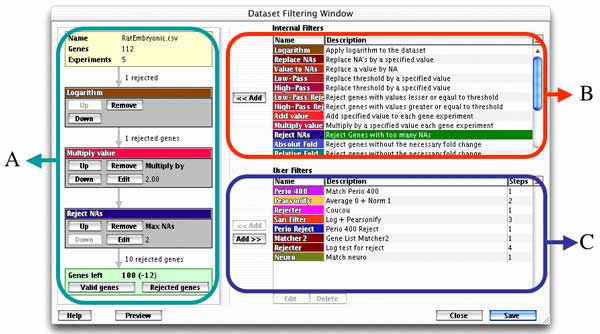
This part of the window
displays the list of user-defined filtering scenarii. A filtering
scenario is a succession of
predefined
or user-defined filters. To add a filter scenario to the pipeline,
simply double click it or click the "
<< Add"
button. To create a user-defined filter scenario, simply design
it in the part A and click the "
Add >>"
button. The filtering scenarioi are stored in the Filter directory
of ArrayMiner and can be exchanged between different computers.(There
are stored in text files with a
.fil extension)